How HashMap works internally
How HashMap works internally?
HashMap uses a HashTable implementation internally, which comprises two important data structures: LinkedList and Array. It’s organized into an array of buckets, where each element represents a separate node. Within the Linked List, the Inner Node class includes attributes such as a hash value, key, value, and a reference to the next node.
Let’s understand this with an example.
Imagine you have a big storage room with many shelves, each labeled with a unique number. Now, you want to store some items like books, shoes, and toys. Instead of randomly placing them on shelves, you use a special code for each item based on its type. For example, books might get a code like “B” and shoes “S” etc.
When you want to find a specific item later, you don’t need to search every shelf. You just generate the code you assigned to it. So, if you’re looking for a book, you know it’s on a shelf labeled “B”. This approach allows you to quickly locate what you require, bypassing the need to search through every shelf and saving valuable time.
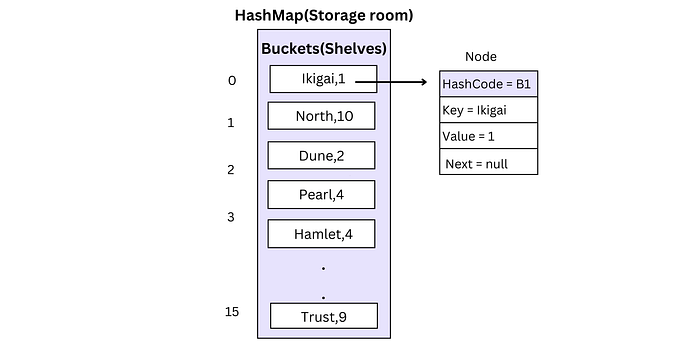
In the above example the storage room represents the HashMap and the shelves represents the buckets to store data and the book represents the data itself.
As demonstrated in the previous example, let’s now discuss how HashMap accomplishes efficient retrieval and deletion of data.
When a user attempts to add a key-value pair to a HashMap. The HashMap performs the following:
1. Buckets:
HashMap initially initializes 16 buckets from 0–15 in heap memory, each of which references a Singly Linked List containing the entries (nodes). A HashMap comprises an array of “buckets,” each capable of accommodating one or multiple key-value pairs. In the above example the shelves represents the buckets.
2. Load Factor and Rehashing:
The load factor specifies how full the HashMap can become before it automatically increases its capacity and rehashes its contents. The default load factor is 75% of the capacity. The threshold of a HashMap is approximately the product of current capacity and load factor. As the number of elements exceeds the load factor times the current capacity, the HashMap capacity will typically be doubled and will be rehashed. Rehashing is the process of re-calculating the hash code of already stored entries. And this is the reason why the order of elements in a HashMap in Java is not consistent.
When initializing a HashMap instance in Java, you have the choice to set both an initial capacity and a load factor. Here’s how you can set the load factor during HashMap creation:
Map<KeyType, ValueType> hashMap = new HashMap<>(16, 0.75f);
3. Hashing:
When you add a key-value pair to the HashMap using the put method, the HashMap class computes the hash code of the key. It then uses this hash code to determine the index of the bucket where the key-value pair should be stored in the array. Hashing is a technique of generating the hashcode of the object. To achieve this hashCode() method is used. hashCode() method of the object class returns the memory reference of an object in integer form. This hash code determines the index within an array called the bucket, where the value will be stored. In the above example hascode for book was “B”.
Note: You can override hashCode() function and give your own implementation.
4. Collision:
A collision occurs when two or more keys hash to the same index (position) within the underlying array, but the keys are not equal.
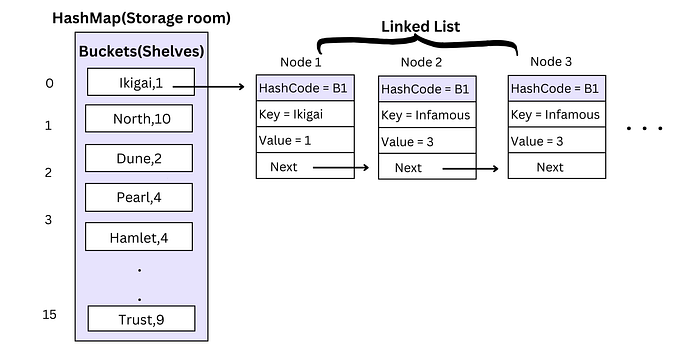
Image in the above example what if two items have the same code, like two books? That’s where HashMaps handle collisions. They cleverly organize items with the same code together, so when you search for a book, you quickly find the shelf labeled “B” and pick the right one. A case where two keys are different but the hash code is same then this is called collision.
HashMaps handle collisions by using a technique called chaining, where multiple key-value pairs with the same hash code are stored in a linked list within the same bucket. When retrieving a value associated with a key, the HashMap iterates through the linked list (if present) in the corresponding bucket to find the correct key-value pair.
5. equals():
When hash collision occurs the equals() method is used to check if the element present at that position is equal, if equal it will simply override the value to the new value, if not it results into collisions.
HashMaps in Java do not allow duplicate keys because they are designed to store key-value pairs, where each key must be unique. This uniqueness ensures that each key is associated with only one value, facilitating efficient retrieval of values based on keys.
Note: The order of elements in a HashMap in Java is not guaranteed to be consistent across different iterations or operations. This is because the internal implementation of HashMap does not preserve the insertion order of elements. While the elements are stored in the HashMap based on their hash codes and bucket indices, the order in which they are stored may change due to factors such as resizing or rehashing.
Changes in Java 8 implementation
Retrieval during collisions was slower before Java 8 because, in earlier versions, HashMaps used a linked list to handle collisions. When multiple keys hashed to the same index (bucket), their key-value pairs were stored in a linked list within that bucket.
During retrieval, the HashMap had to iterate through the entire linked list within the bucket to find the key-value pair corresponding to the desired key. This linear search process had a time complexity of O(n), where n is the number of elements in the linked list. As the number of collisions increased, the length of the linked lists grew, leading to slower retrieval times.
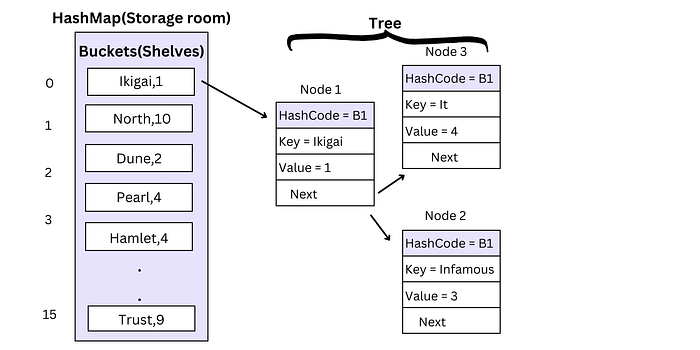
Hence to solve this problem Tree data structure is used instead of Linked list to handle collisions.
In Java 8, when the number of nodes in a single bucket reaches a threshold called Treeify Threshold the HashMap converts the internal structure of that bucket from a linked list to a Tree data structure. All node within the bucket are converted into TreeNode. The HashMap converts the linked list to a balanced tree during rehashing process reducing the time taken for retrieval process from O(n) to O(log(n)).
Also note if the nodes in the bucket reduces to a certain threshold the tree is converted back to linked list. This helps efficient use of memory and balance the performance as Tree takes more memory.